LLM-only RAG for small corpora
Retrieval-augmented generation (RAG) means finding a relevant set of documents in a corpus and generating text based on them. The standard story for LLM RAG is:
- Split your corpus into text chunks
- Generate and store a vector embedding for each chunk
- When you get a query, get an embedding for it and look up related chunks
- Feed those chunks to an LLM and have it answer the question
It’s not complicated conceptually, but 1-3 are basically text search: turning a text query into a list of relevant documents. Because search is a deep domain on which unfathomable engineering effort has been spent, you can put an arbitrarily large amount of work into refining a RAG system.1
LLMs can do retrieval
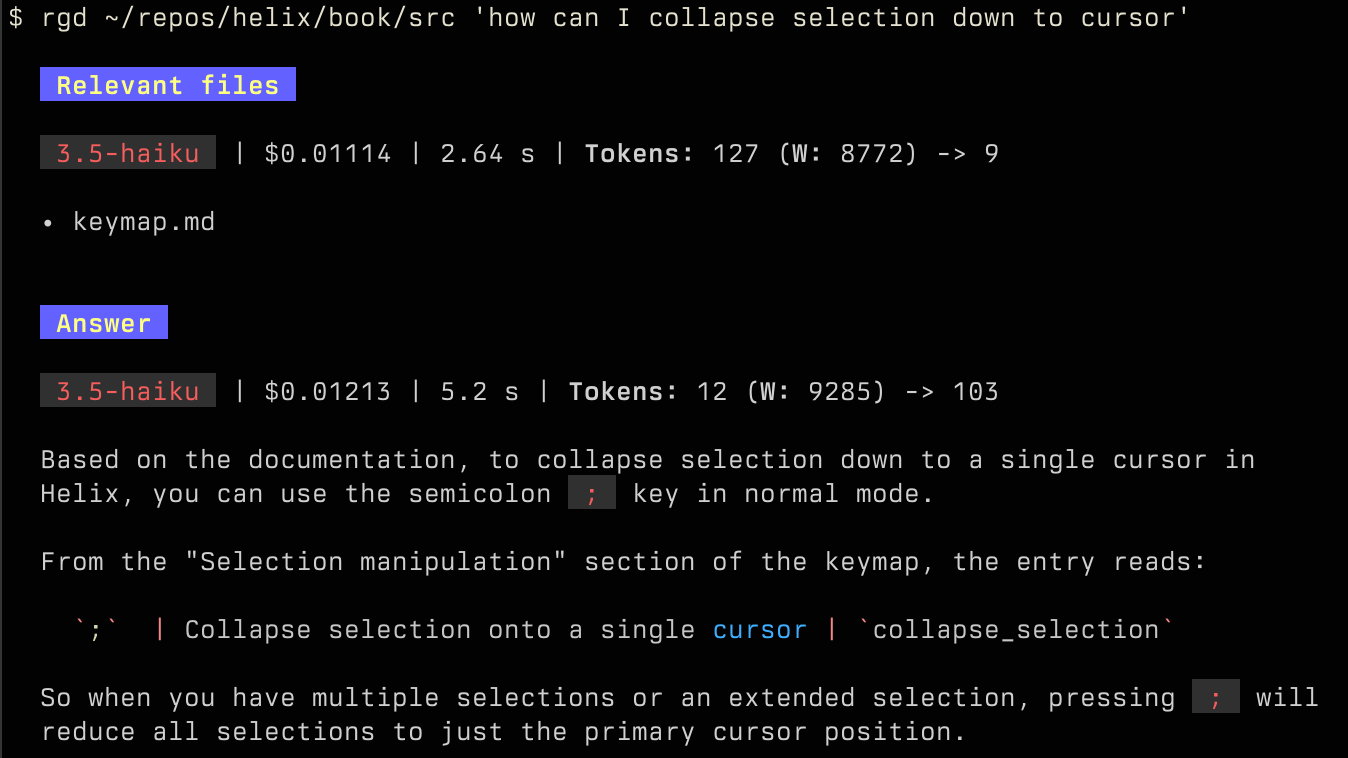
I prefer to put in an arbitrarily small amount of work. Last year I figured out a trick: you don’t need vector stores to do RAG if your corpus is small enough, say under 50 text files. Lots of corpora — like the docs for Jujutsu or React Router or Helix — are small by that definition.2
Instead of doing real search, I mechanically generate an outline of Markdown or AsciiDoc files — extract titles, headings, and a little text content3 — and ask an LLM which documents are relevant to the query. Then I take the full contents of those documents and stick them in a second prompt asking the model to answer the question. It turns out this works reasonably well.
raggedy: a simple implementation
I wrote a CLI in 230 lines of TypeScript called raggedy that demonstrates the idea and I’ve found it quite useful. It doesn’t use any AI frameworks or libraries; it just calls the Anthropic SDK directly.4
Building the “index”
I’m not going to go through all the code in detail here (I could in a followup post if anyone is interested) but I want to call out the “indexing” logic because it’s so simple. I go through any Markdown or AsciiDoc files in the directory and pull out titles, headings, and a text excerpt.5 It’s fast enough that I don’t even bother to store the result. This runs on every invocation of the CLI.
function getIndex(dir: string): Promise<Doc[]> {
const files = walk(dir, { includeDirs: false, exts: ['md', 'adoc'] })
return Array.fromAsync(files, async ({ path }) => {
const content = await Deno.readTextFile(path)
const relPath = relative(dir, path)
const headingPattern = path.endsWith('.adoc') ? /^=+\s+.*/gm : /^#+\s+.*/gm
const headings = (content.match(headingPattern)?.map((h) => h.trim()) || []).join('\n')
const head = content.slice(0, 800)
return { relPath, content, head, headings }
})
}Retrieval and answering
The code is only 60 lines including the prompts and there’s not much to it: here is a question, tell which documents are relevant, respond with a JSON array of paths, etc. Then I parse the JSON,6 pull out the paths, get the full file contents, and make a second prompt: answer the question based on these documents, it’s ok to say “I don’t know,” etc.
I’ll include the two prompts in full because it’s always so weird reading other people’s prompts. The retrieval prompt:
You must determine which documents are likely to be relevant to the user’s question.
- Return at most 4 documents, but return fewer if possible. Avoid returning irrelevant documents!
- Put more relevant documents first
- Your response MUST be an array of relative paths
- The result must be a parseable JSON array of strings
- Do NOT wrap the answer in a markdown code block
- Do NOT include any commentary or explanation
- Do NOT attempt to answer the question
And the answer prompt:
Answer the user’s question concisely based on the above documentation.
- Give a focused answer. The user can look up more detail if necessary.
- The documentation may be truncated, so do not assume it is comprehensive of the corpus or even all relevant documents in the corpus.
- If you do not find the answer in the above sources, say so. You may speculate, but be clear that you are doing so.
- Write naturally in prose. Do not overuse markdown headings and bullets.
- Your answer must be in markdown format.
- This is a one-time answer, not a chat, so don’t prompt for followup questions
Displaying responses
To make things look nice in the terminal, I learned a trick from my
former colleague Justin: build a Markdown string and
pipe it to glow, a CLI for
rendering Markdown. This gets me text formatting and syntax highlighting in code
blocks for free. If there was a good JS lib for this, I’d use it instead
so the script doesn’t depend on an external binary, but I haven’t found
anything as good as glow.
Prompt caching
Anthropic supports prompt caching with a 90% discount on cache hits. By caching the big index prompt, which is always the same for a given corpus, we see a huge price drop on subsequent queries.
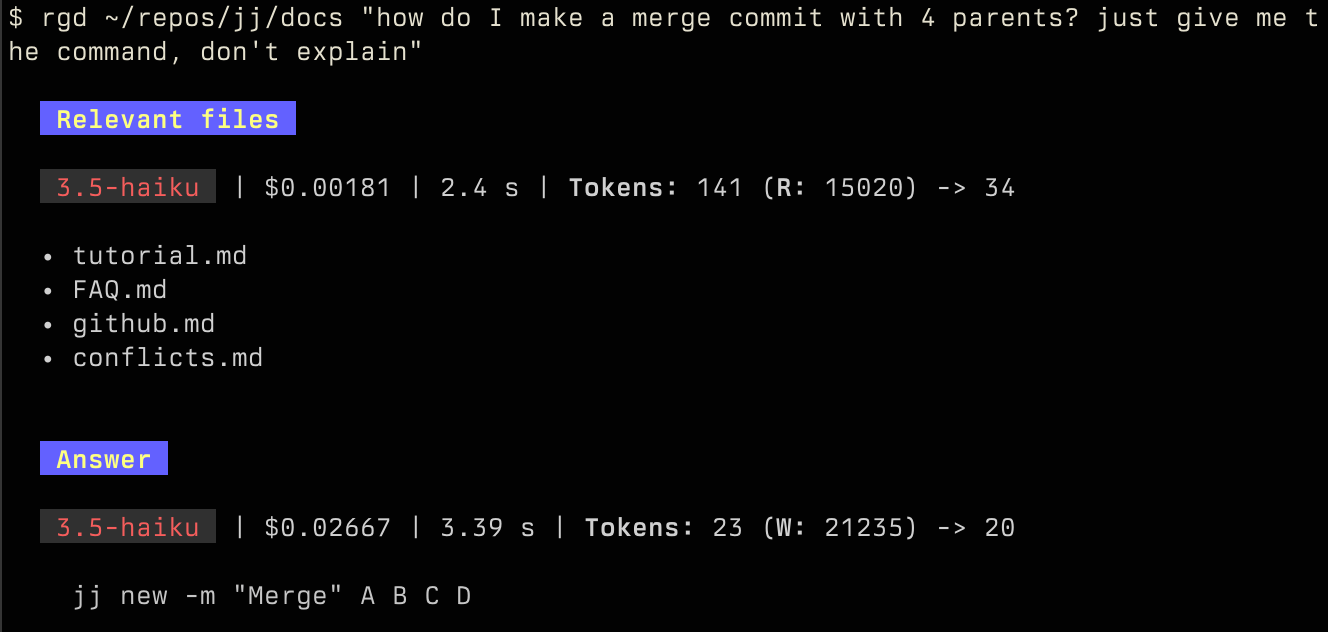
The (R: 15020) means we’re reading 15,000 tokens from cache, and the
price is accordingly about 0.2 cents instead of 2 cents without caching.
Admittedly, this is not always going to do much for personal use — their cache
only lasts about 5 minutes,
so you have to be using it frequently to save money.
Cost and model choice
The above examples use Claude 3.5 Haiku for both retrieval and answering. In my limited experimentation, I didn’t find that Sonnet was that much better at retrieval and it is about 3.5x the price. Sonnet is definitely better at answering, but Haiku is good enough.
The cost of a few cents per query isn’t that bad if you’re using it to do your job better, but you wouldn’t want to put something that expensive online for people to use. Haiku is a mid-price, middle quality model. The most obvious way to cut costs would be to use a cheaper model that compares favorably to Haiku on benchmarks, like Gemini 2.0 Flash. I will have to try that.
Even if we manage to cut the cost of the retrieval step through prompt caching or by making the index smaller, we are still left with a potentially large answering prompt because the full document is the unit of relevance.
If a relevant document is very long but the relevant part is small, you’re paying to process a lot of irrelevant text. It might be possible to use a cheap model to pare down the documents to the most relevant chunks before passing them to a more expensive answering step. We could also try doing the chunking in the indexing step, so that retrieval tells us which chunks are relevant rather than which full documents, but my intuition is that this is risky because there could be too many chunks for it to keep straight.
Further directions
Fetch files from the web
Currently raggedy only works with local files. It would be easy to make it take the URL of a docs directory in a GitHub repo and download the files. It would be a little more work to take arbitrary web URLs and scrape them — it would probably make more sense to use a dedicated tool for that and point raggedy at the directory produced.
Generate keywords to grep for
One idea I haven’t tried yet is to use the LLM (not sure whether in addition to the above or instead) to generate a list of words to grep for in the corpus. This is something like query rewriting. This would compensate for the fact that we are leaving a lot of the document contents out of the outline and therefore could well be missing relevant documents. This would be especially helpful for documents with lots of prose and few section headings. Note that generating keywords to grep for is essential: you can’t have confidence a query will contain exact matches to words in the corpus. This is why keyword search alone could not work for retrieval.
LLM in the loop for indexing
Another approach would be to run each file through a cheap LLM with a big context window during the indexing step, generating an outline or summary for each document and holding onto it. Once you start bringing in outside help for indexing, you’re not far from using embeddings or a traditional search index, though to me a human-readable outline feels more humane and understandable, and you can store it in a text file. You could keep track of a content hash of the original file contents to avoid re-outlining a file that hasn’t changed since the last time you processed it.
Other directions
Huge context windows
Gemini models have context windows of up to 2 million tokens. Especially paired with context caching to reduce costs,7, there could be no need for a separate retrieval step — many corpora are small enough to dump into the prompt in full every time.
Claude Haiku and Sonnet have 200k token context windows, but large prompts are slow and very expensive. For example, passing the full jj docs to 3.5 Haiku using my other LLM CLI took 100k tokens, 8 cents, and 17 seconds vs. 2 cents and 5 or 6 seconds in the above examples. The answer is solid, though on a previous attempt it was a bit weird.

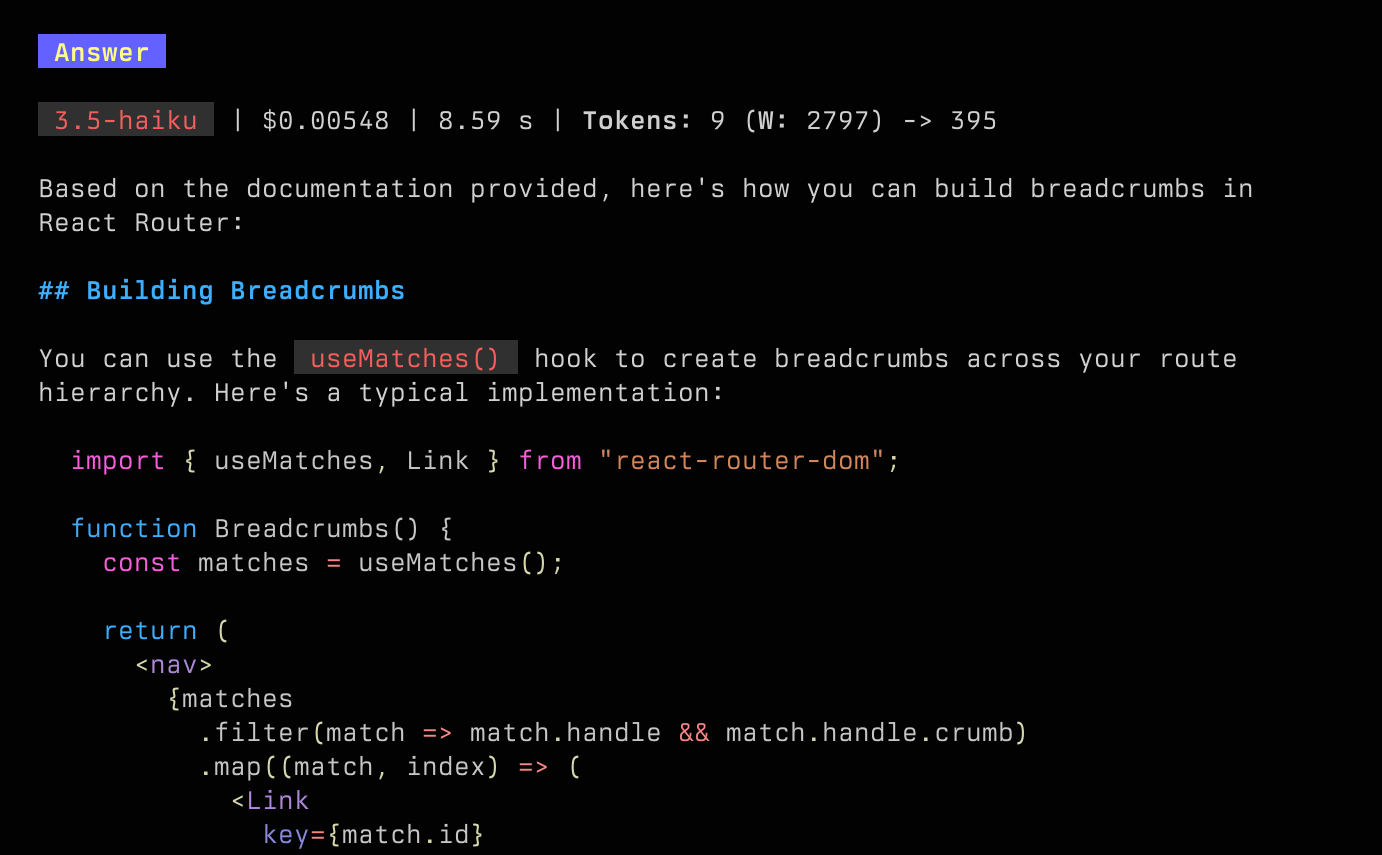
On the other hand, trying the same with Gemini 2.0 Flash takes under 2 seconds and costs 1 cent. Maybe there’s something to this. The breadcrumbs question in the React Router docs was also about 1 cent, but took 5 seconds instead of 2 because the answer was longer.

You could take this to make the LLM-only RAG approach obsolete, but another way to see it is that it increases the scale of corpus where it can work. The approach is bottlenecked by the size of index that can be usefully included in a retrieval prompt. If the index is about an order of magnitude smaller than the corpus and Gemini can handle a 500k token retrieval prompt, that would mean LLM-only RAG can work on a 5 million token corpus.
”Agentic” search
While raggedy does one retrieval and then answers the question, these days more agentic tools are very trendy — where agentic here means it runs for a few more loops and decides for itself when to stop.8 This would allow the model to use the first set of documents retrieved to better understand the question and the corpus and hopefully search more carefully the second time. The best example I’ve seen of this is Claude Code, which can do all kinds of things in a loop while working on your codebase, including text search, web search, and arbitrary shell tasks like running tests and typecheckers.
Of course, once you’re actively crawling the corpus, you might as well
throw in web search and web scraping, and suddenly the tool has stopped
being lazy and you find yourself raising VC money to pay for all your
LLM queries. Over time, we will see the big players handling more of this
functionality within a single API call. I assume this is what o1 and o3
already do — they are able to do reasoning and tool-calling in a loop until
they accomplish a goal. I don’t know whether those activities are
happening fully within the generation loop or are coordinated by
a second system Claude Code, though OpenAI released an Agents
SDK a couple of weeks ago,
which suggests that external coordination is here to stay. The more of these
abilities are built in, the more we lazy developers can do in simple tools like
raggedy and not feel like we’re trying too hard.
Footnotes
-
See A Practical Guide to Implementing DeepSearch/DeepResearch from jina.ai for an example of how much you can suffer if you’re into that. ↩
-
Of course, if your corpus is really small (or if you have manually determined which doc is relevant, essentially making yourself the retrieval system), you can put the entire thing in the prompt every time. This is an underrated approach, but it requires that you either have a tiny corpus or you understand what you’re asking well enough to figure out which document the answer should be in. The value of LLM-powered search is strongest when you don’t know what you’re looking for. ↩
-
Frameworks are often overkill and obscure how simple the underlying logic is. This point is made in the jina.ai post: “An agent framework proved unnecessary, as we needed to stay closer to LLM native behavior to design the system without proxies … a dedicated memory framework remains questionable: We worry it would create an isolation layer between LLMs and developers, and that its syntax sugar might eventually become a bitter obstacle for developers, as we’ve seen with many LLM/RAG framework today.” ↩
-
The excerpt is currently 800 characters, but that’s kind of a lot — you could imagine making it smaller depending on how many documents there are. ↩
-
I did try using the tool use API to get it to return JSON matching a schema, but oddly I found that the results were worse. They may have improved that since. ↩
-
The big providers all do caching differently. OpenAI automatically cache any prefix of a prompt it recognizes, but the discount is only 50%. Anthropic make you ask for caching with a “breakpoint” and charge extra for cache writes, but as I mentioned, their cache hit discount is 90%. For Google, context caches are an explicit resource you have to create and then reference in queries, and they charge $1 per million tokens per hour for storage. The discount on generation is 75%. ↩
-
As Simon Willison points out, everybody talks about agents but nobody can agree on what they are. I like Simon’s phrase “LLMs that run tools in a loop” much better. ↩