Is the "cost of inference" going up or down?
TVs have been getting cheaper for decades, yet people are spending more on them than ever. Does anyone find this puzzling? No, it’s obvious how this happens: the TV you get for $500 is a lot better in 2025 than it was in 2015, and people are happy to keep spending the $500 for the better one rather than spending $200 for a 10 year old TV. Or instead of one $500 TV, maybe they buy two $300 TVs, in which case they’re spending more than 10 years ago. Would anyone describe this situation as “the cost of TVs has gone up?”
And how can TV retailers make money in this situation? Did they expect to keep charging $500 for a TV that’s now really worth $200, and pocket the $300 difference? This is also not a puzzle. The store charges some percentage above what they paid for the TV, and they make some money. If people spend $600 instead of $500, that’s great — they skim the same percentage off a bigger denominator. And if more people buy their first TVs, that’s also great.
Notice all the distinctions we’ve drawn: there’s the average sale price of a single TV — that’s price per unit, which hasn’t necessarily changed a lot. Then there’s price per quality of unit, which has gone down a lot. Then there’s spending per household, which is independent of those, and has probably increased. Then there’s total spending across all households, which has also increased.
Nobody considers this a confusing situation, and nobody says “the cost of TVs has gone up.” Why, then, is Ed Zitron having such a hard time when it comes to LLM inference? It’s exactly the same situation! I recommend going and reading the section on the cost of inference in that post before continuing.
Just like TVs, LLM inference has gotten dramatically cheaper at a given level of quality. The weird thing is Zitron isn’t even disagreeing with that. As he reluctantly put it,
while the costs of old models may have decreased, new models cost about the same
More pointedly, this excellent yet also Zitron-approved WSJ article by Christopher Mims includes a great chart from Epoch AI:
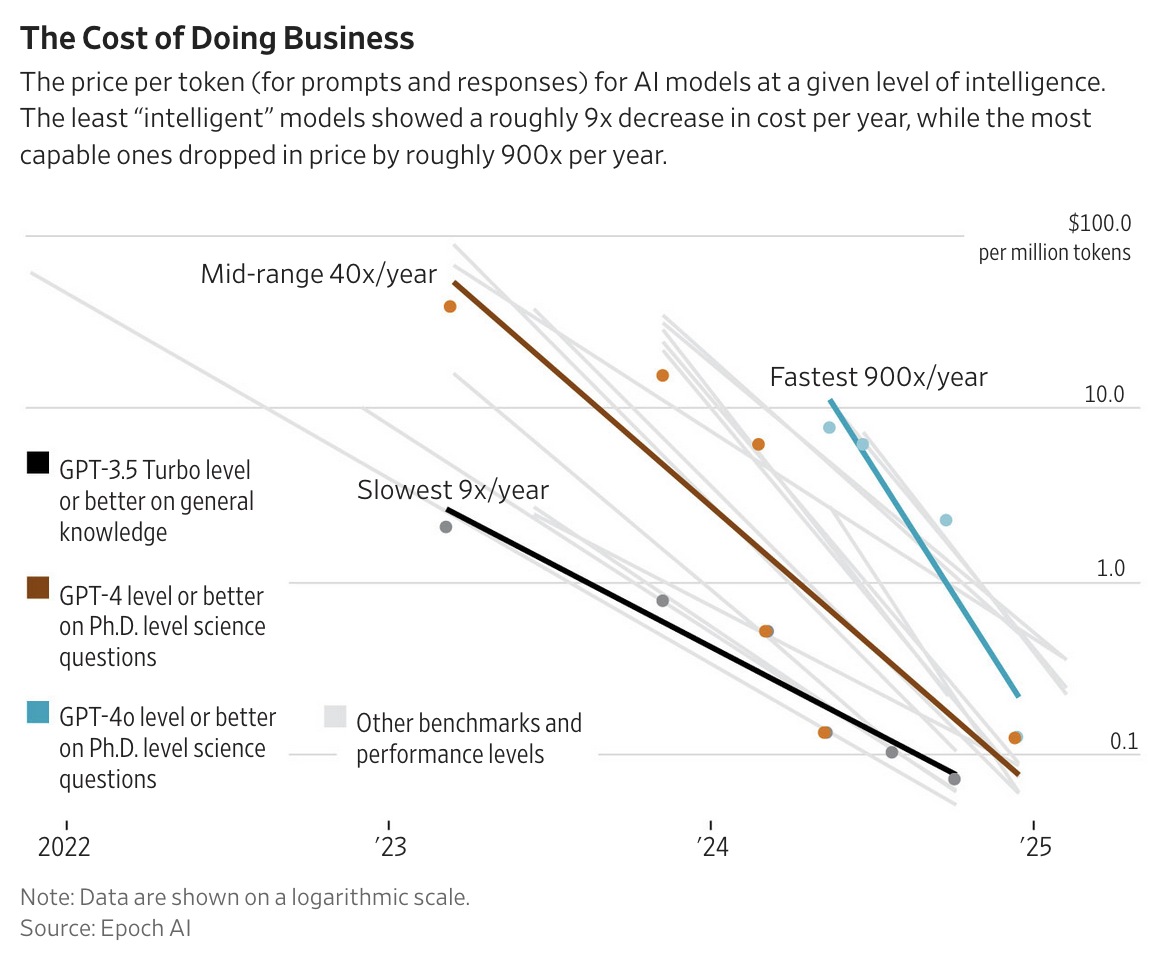
Despite this, people are spending more and more money on LLMs. I don’t think anyone would disagree with that either. The latest available revenue numbers show OpenAI growing from $10B ARR in June to $12B at the end of August, and Anthropic growing from $1B ARR at the beginning of the year to $4B ARR at the beginning of July to $5B at the end of July.
How can this be? Same as TVs: people are choosing to pay more for quality. In other words: if, a year ago, there was something you thought it was worth using an LLM for, today you have three options:
- Do exactly the same thing for much cheaper
- Keep paying the same amount, but now the results are better, or
- Spend more than you did before (whether by using bigger models or more reasoning) to make the result even better than option 2.
Many people, it seems, are choosing options 2 and 3, even though 1 is right there. On top of that, today there are more things worth using an LLM for. So the cost of inference has gone down, but spending has gone up because a) people prefer to pay more for higher quality, and b) people are using LLMs a lot more and for more things.
Again Zitron—to his credit—accurately describes the situation, but doesn’t realize he’s giving away the game entirely if he admits that people are choosing to pay for higher quality.
Because model developers hit a wall of diminishing returns, and the only way to make their models do more was to make them burn more tokens to generate a more accurate response (this is a very simple way of describing reasoning, a thing that OpenAI launched in September 2024 and others followed).
As a result, all the “gains” from “powerful new models” come from burning more and more tokens.
This isn’t entirely right because the newer models are better than older ones even with reasoning off. Zitron also does not seem to know that while reasoning models can use a lot more tokens, nobody is making you do that. Nearly every reasoning model can be used with reasoning off or set to a minimal level. You can use non-reasoning models in coding tools like Cursor, it’s just that people are choosing to spend more on reasoning models because it produces better results. So people are not only choosing to pay higher per-token prices for better (newer) models, they are also choosing to generate more tokens in order to make their results better. They love their new TVs so much they are buying one for every room!
At this point I think I’ve made clear that it’s very odd to describe this situation as “the cost of inference has gone up,” so the question that remains is why Zitron insists on doing so. Zitron’s overarching goal is to show that the LLM industry is going to collapse any day, and as part of that he needs to show that both model providers and LLM wrapper applications like Cursor cannot become profitable businesses. So far, so good! This is a sound argument: if model providers and applications can’t make money, then that is definitely bad for them.
Where I think Zitron goes wrong is that he has come to believe that LLM industry business models require the “cost of inference” to go down for the math to work.
Ask them to explain whether things have actually got cheaper, and if they say they have, ask them why there are no profitable AI companies.
I also predict that there’s going to be a sudden realization in the media that it’s going up, which has kind of already started. The Information had a piece recently about it, where they note that Intuit paid $20 million to Azure last year (primarily for access to OpenAI’s models), and is on track to spend $30 million this year, which “outpaces the company’s revenue growth in the same period, raising questions about how sustainable the spending is and how much of the cost it can pass along to customers.”
Now, we’ve established at length that there are many different things one could mean by “cost of inference”, and Zitron has decided it means per-firm or per-user or total spending. At one point, he gestures at a per-task spending as well:
The problem, however, is that *these are raw token costs, not actual expressions or evaluations of token burn in a practical setting.*
As a result, tasks are taking longer and burning more tokens.
(Which one of those he means doesn’t really matter because they’re all going up, and the following argument applies equally well to all of them.)
My argument is simple: even if you accept Zitron’s weird usage of “cost of inference”, there is no reason to believe that LLM business models require this number to go down. On the contrary, they almost certainly require it to keep going up (I’ll get to that in a minute).
Why does he think it has to go down? He links a blog post called “Future AI bills of $100k/yr per dev” from a company called Kilo that makes a coding assistant. This post argues that for AI dev tools like Cursor,
The bet was that by the following year, the application inference would cost 90% less, creating a $160 gross profit (+80% gross margins). But this didn’t happen, instead of declining the application inference costs actually grew!
I just don’t buy it. Like I said at the beginning, to me this is like saying TV retailers were betting on the price of TVs going down so they could keep charging the same amount and keep the difference. Why would Cursor or any other AI tooling company believe they could keep charging $20 a month for something that costs them $2? It’s obvious that prices are competed down to near the underlying costs in that situation. So, like the TV retailers, the goal is to make some percentage margin on all sales, and then the more sales you have, the more money you make.1
The question, I suppose, is whether model providers and applications are able to make their pricing model work that way and therefore benefit from more and more inference taking place. My contention is that a) yes, they can obviously do that, and b) when they in fact did do that earlier this year, Zitron said it was a sign they were about to go out of business any day now. He also said users were quitting in droves based on a few Reddit posts. But (from the WSJ article mentioned above):
Despite protests from a noisy minority of users, “we didn’t see any significant churn or slowdown in revenue after updating the pricing model,” says Replit CEO Amjad Masad.
Cursor uses flat-rate pricing with various tiers. Zitron made a huge deal of the fact that Cursor had to change their pricing model somewhat earlier this year in order to reflect differences in usage between different users. When Anthropic introduced rate limits to slow down some heavy users, he said “Rate limits are a bad sign” despite them being a universal feature of every API product that has ever existed. So, is it bad for them to have flat pricing without rate limits, or is it bad for them to have usage-based pricing and rate limits?
In Zitron’s analysis, it’s always bad. It’s bad when they raise too little money because they’ll run out. It’s bad when they raise too much money because it means they need it. It’s bad that AI is so little of big tech revenue, but somehow also “Google, Microsoft, Amazon and Meta do not have any other ways to continue showing growth.” Meanwhile, they are posting record revenue and earnings every quarter. While this post focuses on one particularly weak and instructive section of “How To Argue With An AI Booster”, he has been making this same argument for months, and it is hard to find an analysis of his that doesn’t suffer similarly from being forced into the mold of explaining why this means the bubble is about to pop.
One final thought: it should be obvious that none of what I’ve said here has any bearing whatsoever on the question of whether these trends are good or bad. I am just trying to get clear on what the trend is. Whatever your social or political goals are, you cannot possibly achieve them if you start out confused about what is happening.
Footnotes
-
Imagine you’re willing to pay $50 a month directly to OpenAI for some tier of service. It only takes a little bit of added value or stickiness for Cursor to get you paying them $52 instead, $50 of which goes to OpenAI (or a little less because of volume pricing). This is a far better story for both Cursor and OpenAI than the one where inference spending goes way down and Cursor is groveling for a slice of your $2 instead of your $50. ↩